
Cartographie d’audibilité Audioscan Speechmap®
Speechmap® est un système de cartographie de l’audibilité de marque déposée introduit par Audioscan en 1992. Il a été inspiré par les travaux de Margo Skinner et David Pascoe au Central Institute for the Deaf (CID) qui ont développé une méthode d’adaptation basée sur l’amplification d’un signal vocal réel calibré au centre approximatif de la zone auditive. Speechmap® a été le premier mode de réalisation de ce concept dans un système commercial. Il a utilisé des signaux vocaux simulés pour créer une carte de la région de la parole amplifiée dans la zone auditive résiduelle – d’où le nom “Speechmap”. Les études de Stelmachowicz et al (1996) et Scollie et al (2002) ont fourni la preuve que les signaux vocaux simulés utilisés dans Speechmap étaient de bons prédicteurs de la sortie vocale réelle pour les aides auditives à compression de l’époque.
En 2001, l’Audioscan Verifit® a introduit des signaux vocaux réels calibrés dans Speechmap et a été le premier système à utiliser de tels signaux. Audioscan a été le premier innovateur dans l’utilisation de la parole et des signaux de type vocal pour l’ajustement des aides auditives et possède une compréhension inégalée de la science derrière ces méthodes. Cette expertise unique est ce qui rend Speechmap différent des autres noms similaires systèmes de cartographie de l’audibilité.
Audioscan Speechmap: Caractéristiques principales
1) Fournit une variété de signaux de parole réels enregistrés numériquement et permet l’utilisation de la parole en direct.
Pourquoi est-ce important: L’utilisation de matériel vocal enregistré garantit des mesures répétables. La parole enregistrée est le signal de référence (contre le bruit ou les signaux tonaux) qui permet de tester sans interaction négative avec les fonctions adaptatives et ne nécessite donc pas l’utilisation d’un “ mode de vérification ” lorsque les fonctions adaptatives sont désactivées.
2) Les signaux vocaux sont contrôlés en temps réel pour produire un spectre calibré et contrôlé dans le champ sonore ainsi que dans la boîte de test
Pourquoi est-ce important: Les méthodes d’ajustement telles que DSL, NAL-NL1, NAL-NL2 et l’indice d’intelligibilité de la parole (SII) supposent toutes des spectres spécifiques pour la parole à divers efforts vocaux. Si ces spectres spécifiés ne sont pas délivrés à l’aide auditive lors de l’appariement de ces cibles d’ajustement ou lors du calcul du SII, des erreurs significatives en résulteront.
3) Tous les passages de parole amplifiés, enregistrés et en direct, sont analysés dans des bandes de 1/3 d’octave sur plusieurs secondes pour fournir le spectre vocal moyen à long terme (LTASS).
Pourquoi est-ce important: Les cibles d’ajustement pour DSL, NAL-NL1, NAL-NL2 et le calcul SII supposent tous un LTASS obtenu en faisant la moyenne de 1/3 octaves de bandes de parole sur plusieurs secondes. Lorsque les signaux à large bande sont analysés dans des bandes étroites pour produire un spectre, le SPL dans chaque bande dépend de la largeur de la bande.
Par exemple, le spectre d’un signal vocal apparaîtra près de 10 dB plus bas sur les systèmes qui utilisent des bandes d’analyse 1/24 octave plutôt que l’analyse 1/3 octave utilisée dans Speechmap. Lorsque des signaux fluctuants sont analysés, le temps moyen utilisé pour calculer le SPL dans chaque bande influence le résultat. Un LTASS précis ne peut être obtenu qu’en utilisant des durées moyennes de 10 secondes ou plus. Faire correspondre des cibles ou calculer le SII à l’aide de courbes obtenues à l’aide de bandes autres que 1/3 d’octave ou de temps d’analyse inférieurs à 10 secondes entraînera des erreurs dans le SII et dans l’ajustement.
4) La région de la parole amplifiée (banane de la parole) est calculée à partir des propriétés statistiques de la parole mesurée en utilisant un temps d’intégration similaire à celui de l’oreille.
Pourquoi est-ce important: La plage entre les vallées de la parole et les pics de parole (région de la parole) est souvent décrite comme s’étendant de 18 dB en dessous du LTASS à 12 dB au-dessus. Cependant, cela dépend du locuteur et du fonctionnement du système de compression dans l’aide auditive. Plutôt que de simplement dessiner la région de la parole dans une plage de 30 dB autour du LTASS, le mappage d’audibilité de Speechmap montre le haut de la région de la parole lorsque le SPL dépasse 1% du temps (le 99e centile) et le bas de la région de la parole comme le SPL dépassé 70% du temps (30e centile), dans chaque bande d’octave 1/3. Cette plage changera avec les locuteurs et sera réduite par des compresseurs syllabiques, montrant clairement les effets des ajustements des paramètres de compression.
La région de la parole dépend également de la façon dont elle est mesurée. L’utilisation d’un intervalle de mesure très court se traduira par des pics plus élevés et des vallées plus basses et une région de la parole plus large. Par exemple, Byrne et al (1994) ont signalé des pics instantanés de 25 à 30 dB au-dessus du LTASS dans la parole non amplifiée. Cependant, l’oreille est environ 10 à 20 dB moins sensible aux sons qui ne durent que quelques millisecondes (ms) qu’aux sons qui durent 100 ms ou plus, tels que ceux utilisés pour mesurer le seuil et l’UCL. Le spectre des pics de parole, mesuré à des intervalles de 1 à 10 ms, peut être de 10 à 20 dB au-dessus du seuil (ou UCL) sans que la parole soit audible (ou inconfortable). Le mappage d’audibilité de Speechmap utilise des intervalles de mesure de 128 ms lors du développement de la région de la parole. Cela signifie qu’une région vocale Speechmap avec des pics au seuil sera détectable, une région qui est entièrement supérieure au seuil sera audible au maximum et une qui s’étend au-dessus de l’UCL sera inconfortable.
La cartographie d’audibilité Speechmap d’Audioscan est fermement ancrée dans plus de 65 ans de science de la parole, de Dunn & White (1940) à Byrne et al (1994). Lorsque vous avez besoin de savoir ce qui se passe réellement avec un signal vocal, les détails comptent.
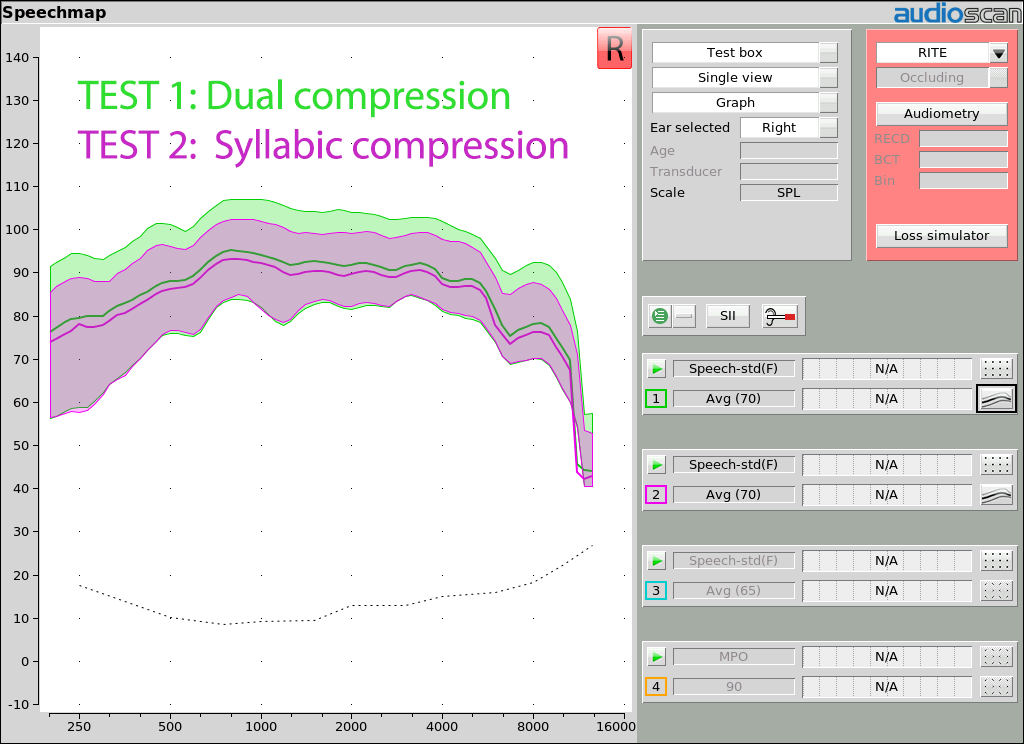
Exemple 1: La compression syllabique réduit la largeur de la région de la parole.
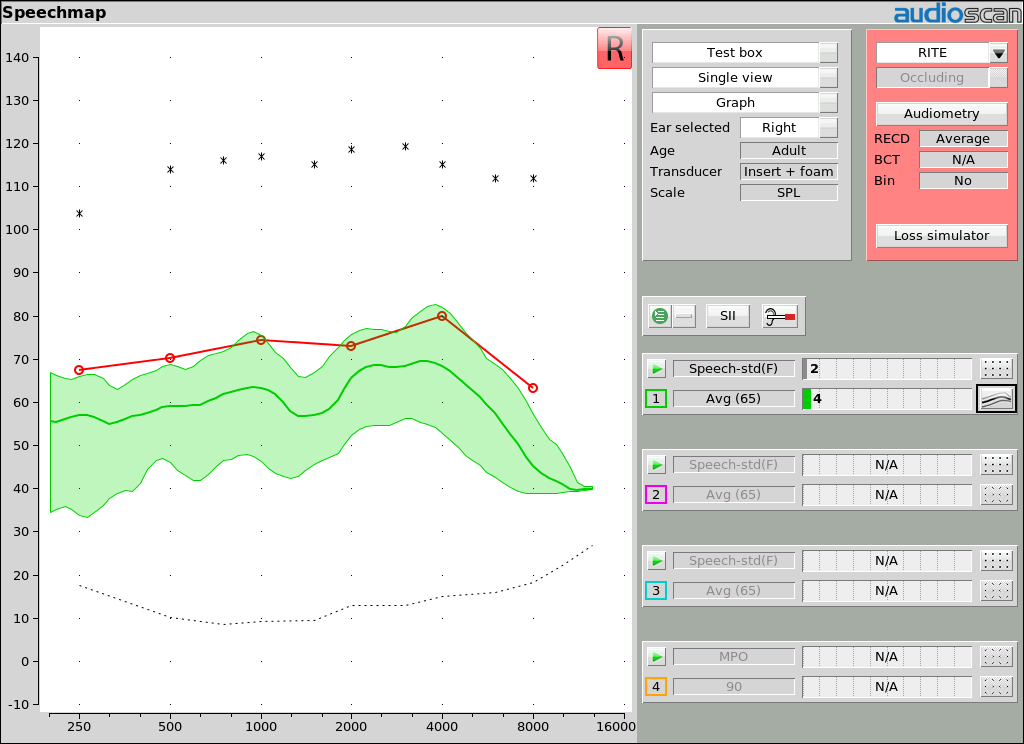
Exemple 2: pics de parole au seuil, SII = 4. La parole est détectable mais n’est pas comprise.
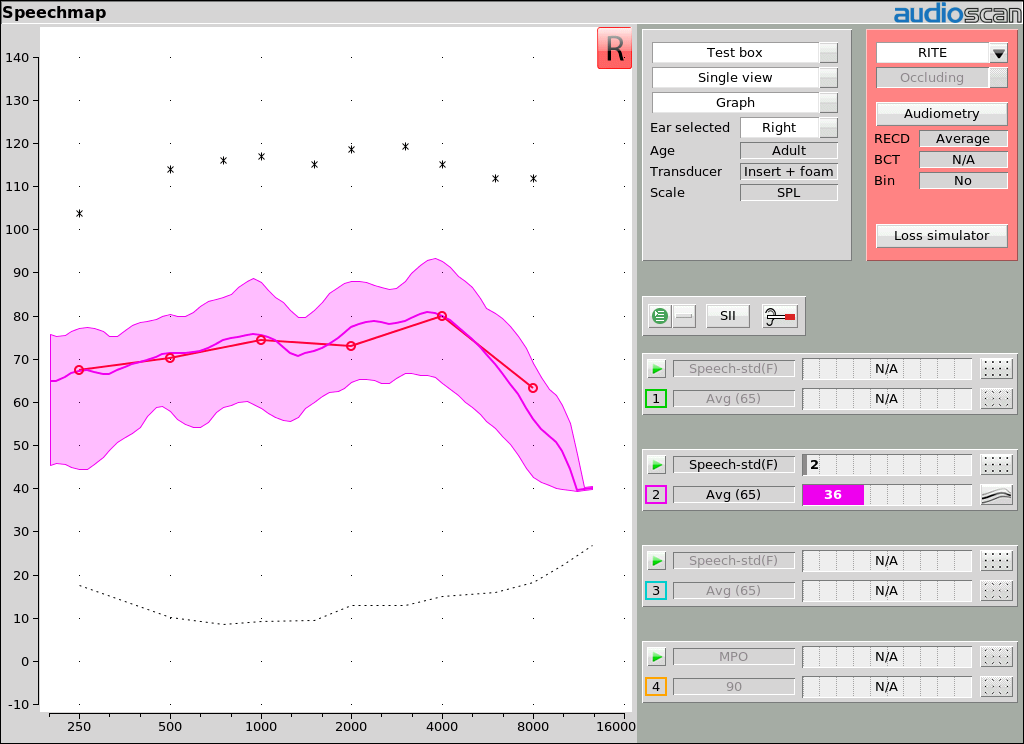
Exemple 3: LTASS au seuil donne un SII de 30-40, indiquant 60-80% correct sur le test CST (théorique pour les normales).
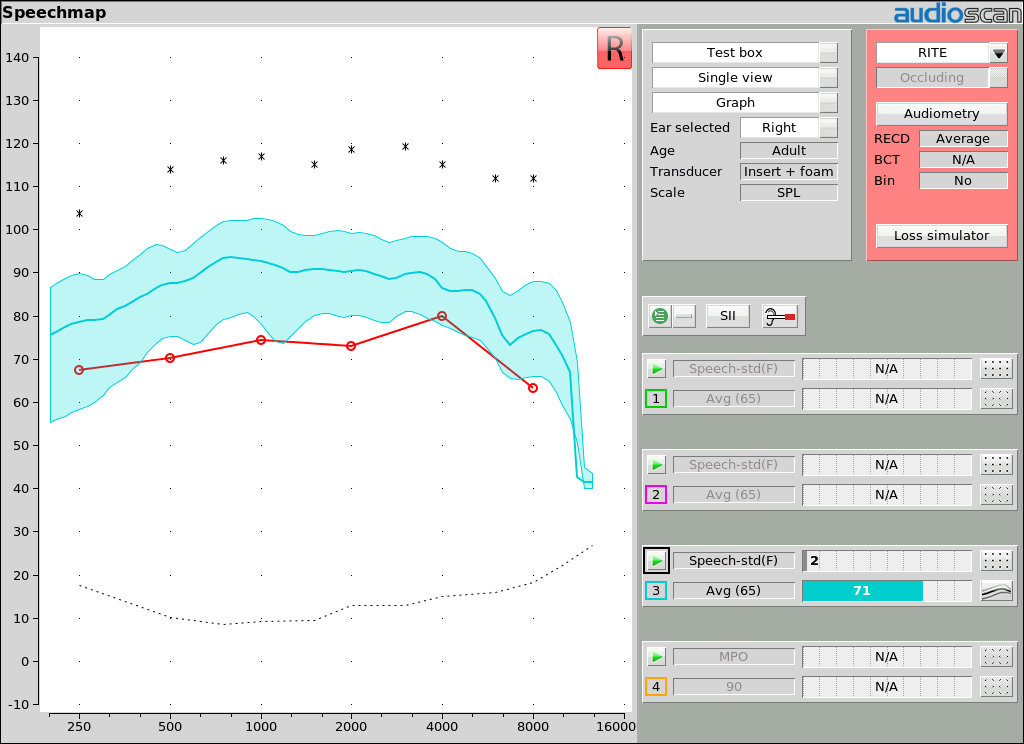
Exemple 4: une région de la parole dépassant le seuil se traduira par un SII supérieur à 70 qui prédit un score de 100% sur le CST. Fournir un gain supplémentaire pour la parole à ce niveau (65 dB SPL) n’augmentera pas la compréhension de ce type de matériel vocal.